这基本是一个不可能完成的任务,不过作为RNN的练习,还是一个不错的题目:有数据,有场景,有吸引力。本案例主要参考:https://github.com/DarkKnight1991/Stock-Price-Prediction ,这是一个many-to-one的RNN案例,即通过前60日股价数据(open,close,high,low,volume)预测下一日的收盘价,其中feature size=5。
先上运行结果图: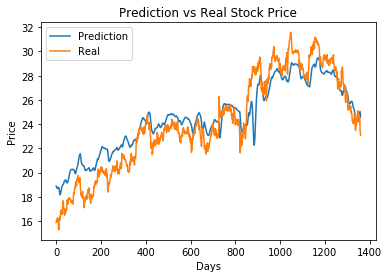
导入必要的包
这里使用了sklearn包的MinMaxScaler进行数据的预处理。
# import tensorflow as tf
# import tensorflow.keras as keras
import numpy as np
import os
import sys
import time
import pandas as pd
from tqdm._tqdm_notebook import tqdm_notebook
import pickle
from keras.models import Sequential, load_model
from keras.layers import Dense, Dropout
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau, CSVLogger
from keras import optimizers
# from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import logging
from matplotlib import pyplot as plt
Using TensorFlow backend.
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
logging.getLogger("tensorflow").setLevel(logging.ERROR)
os.environ['TZ'] = 'Asia/Shanghai' # to set timezone; needed when running on cloud
time.tzset()
集中设置参数
params = {
"batch_size": 20, # 20<16<10, 25 was a bust
"epochs": 300, # 由于启用了earlyStopping机制,通常会提前终止
"lr": 0.00010000, # 学习率
"time_steps": 60 # RNN的滑动窗口大小,这是使用60日的数据预测下一日的某个特征
}
iter_changes = "dropout_layers_0.4_0.4"
DATA_FILE="ge.us.txt"
PATH_TO_DRIVE_ML_DATA="./"
INPUT_PATH = PATH_TO_DRIVE_ML_DATA+"inputs"
OUTPUT_PATH = PATH_TO_DRIVE_ML_DATA+"outputs/"+time.strftime("%Y-%m-%d")+"/"+iter_changes
TIME_STEPS = params["time_steps"]
BATCH_SIZE = params["batch_size"]
stime = time.time()
# check if directory already exists
if not os.path.exists(OUTPUT_PATH):
os.makedirs(OUTPUT_PATH)
print("Directory created", OUTPUT_PATH)
else:
os.rename(OUTPUT_PATH, OUTPUT_PATH+str(stime))
os.makedirs(OUTPUT_PATH)
print("Directory recreated", OUTPUT_PATH)
Directory created ./outputs/2019-05-12/dropout_layers_0.4_0.4
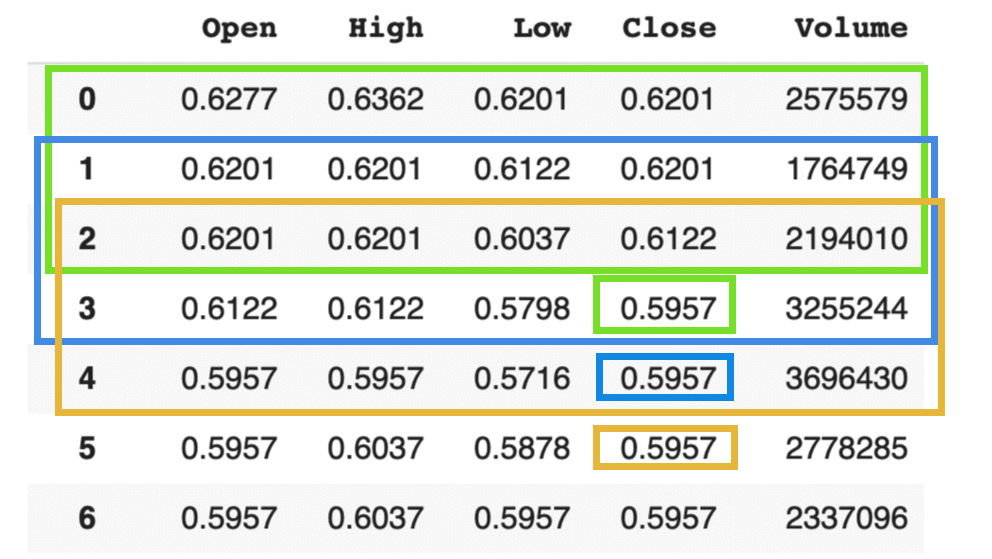
构造训练数据的方法参见下图,注意颜色相同的矩形块框出了输入数据和预测数据,图中的窗口尺寸(time_steps)是3,即使用前3天的数据预测下一日的收盘价。显然,如果样本数为N,则可划分的输入样本数为N-time_steps。
def print_time(text, stime):
seconds = (time.time()-stime)
print(text, seconds//60,"minutes : ",np.round(seconds%60),"seconds")
def trim_dataset(mat,batch_size):
"""
trims dataset to a size that's divisible by BATCH_SIZE
"""
no_of_rows_drop = mat.shape[0]%batch_size
if no_of_rows_drop > 0:
return mat[:-no_of_rows_drop]
else:
return mat
def build_timeseries(mat, y_col_index):
"""
Converts ndarray into timeseries format and supervised data format. Takes first TIME_STEPS
number of rows as input and sets the TIME_STEPS+1th data as corresponding output and so on.
:param mat: ndarray which holds the dataset
:param y_col_index: index of column which acts as output
:return: returns two ndarrays-- input and output in format suitable to feed
to LSTM.
"""
# total number of time-series samples would be len(mat) - TIME_STEPS
dim_0 = mat.shape[0] - TIME_STEPS
dim_1 = mat.shape[1]
x = np.zeros((dim_0, TIME_STEPS, dim_1))
y = np.zeros((dim_0,))
print("dim_0",dim_0)
for i in tqdm_notebook(range(dim_0)):
x[i] = mat[i:TIME_STEPS+i]
y[i] = mat[TIME_STEPS+i, y_col_index]
# if i < 10:
# print(i,"-->", x[i,-1,:], y[i])
print("length of time-series i/o",x.shape,y.shape)
return x, y
stime = time.time()
print(os.listdir(INPUT_PATH))
['ge.us.txt']
构造训练数据
Again,RNN的输入数据要求的shape是(batch_size, time_steps, feature_size)
df_ge = pd.read_csv(os.path.join(INPUT_PATH, DATA_FILE))
print(df_ge.shape)
print(df_ge.tail())
tqdm_notebook.pandas('Processing...')
print(df_ge.dtypes)
train_cols = ["Open","High","Low","Close","Volume"]
df_train, df_test = train_test_split(df_ge, train_size=0.8, test_size=0.2, shuffle=False)
print("Train--Test size", len(df_train), len(df_test))
# scale the feature MinMax, build array
x = df_train.loc[:,train_cols].values
min_max_scaler = MinMaxScaler()
x_train = min_max_scaler.fit_transform(x)
x_test = min_max_scaler.transform(df_test.loc[:,train_cols])
print("Deleting unused dataframes of total size(KB)",
(sys.getsizeof(df_ge)+sys.getsizeof(df_train)+sys.getsizeof(df_test))//1024)
del df_ge
del df_test
del df_train
del x
print("Are any NaNs present in train/test matrices?",np.isnan(x_train).any(), np.isnan(x_train).any())
x_t, y_t = build_timeseries(x_train, 3)
x_t = trim_dataset(x_t, BATCH_SIZE)
y_t = trim_dataset(y_t, BATCH_SIZE)
print("Batch trimmed x_t size",x_t.shape)
print("Batch trimmed y_t size",y_t.shape)
(14058, 7)
Date Open High Low Close Volume OpenInt
14053 2017-11-06 20.52 20.530 20.08 20.13 60641787 0
14054 2017-11-07 20.17 20.250 20.12 20.21 41622851 0
14055 2017-11-08 20.21 20.320 20.07 20.12 39672190 0
14056 2017-11-09 20.04 20.071 19.85 19.99 50831779 0
14057 2017-11-10 19.98 20.680 19.90 20.49 100698474 0
Date object
Open float64
High float64
Low float64
Close float64
Volume int64
OpenInt int64
dtype: object
Train--Test size 11246 2812
Deleting unused dataframes of total size(KB) 3267
Are any NaNs present in train/test matrices? False False
dim_0 11186
HBox(children=(IntProgress(value=0, max=11186), HTML(value='')))
length of time-series i/o (11186, 60, 5) (11186,)
Batch trimmed x_t size (11180, 60, 5)
Batch trimmed y_t size (11180,)
创建训练模型
def create_model():
lstm_model = Sequential()
# (batch_size, timesteps, data_dim)
lstm_model.add(LSTM(100, batch_input_shape=(BATCH_SIZE, TIME_STEPS, x_t.shape[2]),
dropout=0.0, recurrent_dropout=0.0, stateful=True, return_sequences=True,
kernel_initializer='random_uniform'))
lstm_model.add(Dropout(0.4))
lstm_model.add(LSTM(60, dropout=0.0))
lstm_model.add(Dropout(0.4))
lstm_model.add(Dense(20,activation='relu'))
lstm_model.add(Dense(1,activation='sigmoid'))
# 在这里SGD很难得到理想的结果,RMSprop一般可以比较好的收敛
optimizer = optimizers.RMSprop(lr=params["lr"])
#optimizer = optimizers.SGD(lr=0.000001, decay=1e-6, momentum=0.9, nesterov=True)
lstm_model.compile(loss='mean_squared_error', optimizer=optimizer)
return lstm_model
model = None
try:
model = pickle.load(open("lstm_model", 'rb'))
print("Loaded saved model:",model)
model.summary()
except FileNotFoundError:
print("Model not found")
Model not found
准备测试数据和验证数据
x_temp, y_temp = build_timeseries(x_test, 3)
x_val, x_test_t = np.split(trim_dataset(x_temp, BATCH_SIZE),2)
y_val, y_test_t = np.split(trim_dataset(y_temp, BATCH_SIZE),2)
print("Test size", x_test_t.shape, y_test_t.shape, x_val.shape, y_val.shape)
dim_0 2752
HBox(children=(IntProgress(value=0, max=2752), HTML(value='')))
length of time-series i/o (2752, 60, 5) (2752,)
Test size (1370, 60, 5) (1370,) (1370, 60, 5) (1370,)
BATCH_SIZE对执行速度影响很大,以下是一些测试结果:
| BATCH_SIZE | 时间(s/epoch) |
|---|---|
| 20 | 140 |
| 512 | 5 |
但是,过大的batch_size会影响预测结果,参见:https://datascience.stackexchange.com/questions/16807/why-mini-batch-size-is-better-than-one-single-batch-with-all-training-data
is_update_model = True
if model is None or is_update_model:
from keras import backend as K
print("Building model...")
print("checking if GPU available", K.tensorflow_backend._get_available_gpus())
model = create_model()
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1,
patience=40, min_delta=0.0001)
# mcp = ModelCheckpoint(os.path.join(OUTPUT_PATH,
# "best_model.h5"), monitor='val_loss', verbose=1,
# save_best_only=True, save_weights_only=False, mode='min', period=1)
# Not used here. But leaving it here as a reminder for future
r_lr_plat = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=30,
verbose=0, mode='auto', min_delta=0.0001, cooldown=0, min_lr=0)
csv_logger = CSVLogger(os.path.join(OUTPUT_PATH, 'training_log_' + time.ctime().replace(" ","_") + '.log'), append=True)
history = model.fit(x_t, y_t, epochs=params["epochs"], verbose=1, batch_size=BATCH_SIZE,
shuffle=False, validation_data=(trim_dataset(x_val, BATCH_SIZE),
trim_dataset(y_val, BATCH_SIZE)), callbacks=[es, csv_logger])
# print("saving model...")
# pickle.dump(model, open("lstm_model", "wb"))
Building model...
checking if GPU available []
Train on 11180 samples, validate on 1360 samples
Epoch 1/300
11180/11180 [==============================] - 55s 5ms/step - loss: 0.0214 - val_loss: 0.0091
Epoch 2/300
11180/11180 [==============================] - 53s 5ms/step - loss: 0.0032 - val_loss: 0.0042
Epoch 3/300
11180/11180 [==============================] - 53s 5ms/step - loss: 0.0019 - val_loss: 0.0042
Epoch 4/300
11180/11180 [==============================] - 61s 5ms/step - loss: 0.0017 - val_loss: 0.0032
Epoch 5/300
11180/11180 [==============================] - 55s 5ms/step - loss: 0.0016 - val_loss: 0.0033
Epoch 6/300
11180/11180 [==============================] - 55s 5ms/step - loss: 0.0014 - val_loss: 0.0026
Epoch 7/300
11180/11180 [==============================] - 55s 5ms/step - loss: 0.0013 - val_loss: 0.0024
Epoch 8/300
11180/11180 [==============================] - 55s 5ms/step - loss: 0.0012 - val_loss: 0.0019
Epoch 9/300
11180/11180 [==============================] - 55s 5ms/step - loss: 0.0011 - val_loss: 0.0017
Epoch 10/300
11180/11180 [==============================] - 57s 5ms/step - loss: 0.0012 - val_loss: 0.0022
Epoch 11/300
11180/11180 [==============================] - 54s 5ms/step - loss: 0.0011 - val_loss: 0.0019
Epoch 12/300
11180/11180 [==============================] - 54s 5ms/step - loss: 0.0012 - val_loss: 0.0017
Epoch 13/300
11180/11180 [==============================] - 54s 5ms/step - loss: 0.0010 - val_loss: 0.0017
Epoch 14/300
11180/11180 [==============================] - 54s 5ms/step - loss: 0.0010 - val_loss: 0.0022
Epoch 15/300
11180/11180 [==============================] - 54s 5ms/step - loss: 0.0010 - val_loss: 0.0021
Epoch 16/300
11180/11180 [==============================] - 54s 5ms/step - loss: 9.4909e-04 - val_loss: 0.0027
Epoch 17/300
11180/11180 [==============================] - 57s 5ms/step - loss: 9.8950e-04 - val_loss: 0.0022
Epoch 18/300
11180/11180 [==============================] - 55s 5ms/step - loss: 9.2450e-04 - val_loss: 0.0029
Epoch 19/300
11180/11180 [==============================] - 55s 5ms/step - loss: 9.4218e-04 - val_loss: 0.0032
Epoch 20/300
11180/11180 [==============================] - 55s 5ms/step - loss: 9.4109e-04 - val_loss: 0.0025
Epoch 21/300
11180/11180 [==============================] - 55s 5ms/step - loss: 8.2315e-04 - val_loss: 0.0035
Epoch 22/300
11180/11180 [==============================] - 60s 5ms/step - loss: 8.8774e-04 - val_loss: 0.0031
Epoch 23/300
11180/11180 [==============================] - 53s 5ms/step - loss: 8.8159e-04 - val_loss: 0.0035
Epoch 24/300
11180/11180 [==============================] - 52s 5ms/step - loss: 8.9777e-04 - val_loss: 0.0035
Epoch 25/300
11180/11180 [==============================] - 53s 5ms/step - loss: 8.5882e-04 - val_loss: 0.0028
Epoch 26/300
11180/11180 [==============================] - 53s 5ms/step - loss: 8.1193e-04 - val_loss: 0.0033
Epoch 27/300
11180/11180 [==============================] - 55s 5ms/step - loss: 8.7489e-04 - val_loss: 0.0027
Epoch 28/300
11180/11180 [==============================] - 65s 6ms/step - loss: 7.7182e-04 - val_loss: 0.0029
Epoch 29/300
11180/11180 [==============================] - 65s 6ms/step - loss: 7.8986e-04 - val_loss: 0.0029
Epoch 30/300
11180/11180 [==============================] - 58s 5ms/step - loss: 7.4132e-04 - val_loss: 0.0039
Epoch 31/300
11180/11180 [==============================] - 54s 5ms/step - loss: 7.8840e-04 - val_loss: 0.0033
Epoch 32/300
11180/11180 [==============================] - 57s 5ms/step - loss: 7.2762e-04 - val_loss: 0.0035
Epoch 33/300
11180/11180 [==============================] - 58s 5ms/step - loss: 6.8286e-04 - val_loss: 0.0038
Epoch 34/300
11180/11180 [==============================] - 56s 5ms/step - loss: 7.4651e-04 - val_loss: 0.0035
Epoch 35/300
11180/11180 [==============================] - 56s 5ms/step - loss: 6.8999e-04 - val_loss: 0.0036
Epoch 36/300
11180/11180 [==============================] - 55s 5ms/step - loss: 6.7234e-04 - val_loss: 0.0035
Epoch 37/300
11180/11180 [==============================] - 56s 5ms/step - loss: 6.3937e-04 - val_loss: 0.0041
Epoch 38/300
11180/11180 [==============================] - 59s 5ms/step - loss: 6.5488e-04 - val_loss: 0.0033
Epoch 39/300
11180/11180 [==============================] - 55s 5ms/step - loss: 6.1496e-04 - val_loss: 0.0030
Epoch 40/300
11180/11180 [==============================] - 55s 5ms/step - loss: 6.4524e-04 - val_loss: 0.0034
Epoch 41/300
11180/11180 [==============================] - 60s 5ms/step - loss: 6.2799e-04 - val_loss: 0.0029
Epoch 42/300
11180/11180 [==============================] - 58s 5ms/step - loss: 6.0425e-04 - val_loss: 0.0031
Epoch 43/300
11180/11180 [==============================] - 59s 5ms/step - loss: 5.8090e-04 - val_loss: 0.0031
Epoch 44/300
11180/11180 [==============================] - 57s 5ms/step - loss: 6.1104e-04 - val_loss: 0.0028
Epoch 45/300
11180/11180 [==============================] - 59s 5ms/step - loss: 5.8567e-04 - val_loss: 0.0030
Epoch 46/300
11180/11180 [==============================] - 52s 5ms/step - loss: 6.1423e-04 - val_loss: 0.0028
Epoch 47/300
11180/11180 [==============================] - 62s 6ms/step - loss: 5.9890e-04 - val_loss: 0.0027
Epoch 48/300
11180/11180 [==============================] - 54s 5ms/step - loss: 5.6064e-04 - val_loss: 0.0027
Epoch 49/300
11180/11180 [==============================] - 60s 5ms/step - loss: 5.4715e-04 - val_loss: 0.0026
Epoch 00049: early stopping
#model.evaluate(x_test_t, y_test_t, batch_size=BATCH_SIZE)
预测
根据x_test_t进行预测
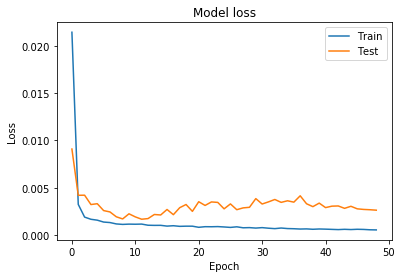
# Visualize the training data
from matplotlib import pyplot as plt
plt.figure()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'])
plt.show()
plt.savefig(os.path.join(OUTPUT_PATH, 'train_vis_BS_'+str(BATCH_SIZE)+"_"+time.ctime()+'.png'))
<Figure size 432x288 with 0 Axes>
def plot_pred(pred, real):
"""绘制预测和实际的比较图"""
plt.figure()
plt.plot(pred)
plt.plot(real)
plt.title('Prediction vs Real Stock Price')
plt.ylabel('Price')
plt.xlabel('Days')
plt.legend(['Prediction', 'Real'])
plt.show()
y_pred = model.predict(trim_dataset(x_test_t, BATCH_SIZE), batch_size=BATCH_SIZE)
print(y_pred)
y_pred = y_pred.flatten()
y_test_t = trim_dataset(y_test_t, BATCH_SIZE)
error = mean_squared_error(y_test_t, y_pred)
print("Error is", error, y_pred.shape, y_test_t.shape)
print(y_pred[0:15])
print(y_test_t[0:15])
y_pred_org = (y_pred * min_max_scaler.data_range_[3]) + min_max_scaler.data_min_[3] # min_max_scaler.inverse_transform(y_pred)
y_test_t_org = (y_test_t * min_max_scaler.data_range_[3]) + min_max_scaler.data_min_[3] # min_max_scaler.inverse_transform(y_test_t)
print(y_pred_org[0:15])
print(y_test_t_org[0:15])
# Visualize the prediction
plot_pred(y_pred_org, y_test_t_org)
plt.savefig(os.path.join(OUTPUT_PATH, 'pred_vs_real_BS'+str(BATCH_SIZE)+"_"+time.ctime()+'.png'))
print_time("program completed ", stime)
[[0.38702852]
[0.38576546]
[0.38440943]
...
[0.5161562 ]
[0.5116954 ]
[0.5070858 ]]
Error is 0.001015373340902301 (1360,) (1360,)
[0.38702852 0.38576546 0.38440943 0.38376644 0.3833659 0.38271877
0.38277936 0.38346294 0.38426045 0.38487393 0.38513672 0.38473445
0.38368103 0.38282415 0.38073507]
[0.32378063 0.32499919 0.32800358 0.32905407 0.32905407 0.33031465
0.32943225 0.33205846 0.32659593 0.32747834 0.31770881 0.31092267
0.31258244 0.32378063 0.32592362]
[18.88041 18.820292 18.755749 18.725145 18.70608 18.67528 18.678162
18.7107 18.748657 18.777857 18.790365 18.77122 18.721079 18.680294
18.58086 ]
[15.87 15.928 16.071 16.121 16.121 16.181 16.139 16.264 16.004 16.046
15.581 15.258 15.337 15.87 15.972]
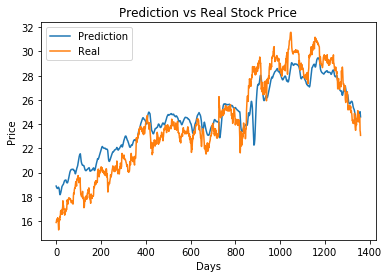
program completed 45.0 minutes : 55.0 seconds
<Figure size 432x288 with 0 Axes>
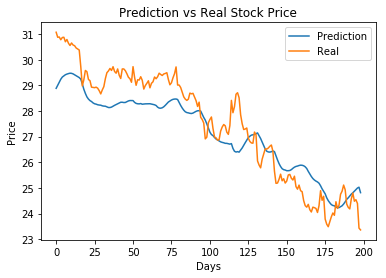
最近200天的走势预测
y_pred_200 = y_pred_org[-200:-1]
y_test_t_200 = y_test_t_org[-200:-1]
plot_pred(y_pred_200,y_test_t_200)
后记
- 如何逐步的观察预测的结果?比如给出前60天的数据作为x_test,然后只预测出下一天的收盘价?
- 如果预测是开盘价呢?
- 改造成many-to-many的案例,即根据前N天的数据预测后M天的收盘价
- 如何显示真实的日期?
